Example of Program Execution (2)

왼쪽에 파란색으로 표시된 것은 메모리, 오른쪽에 회색으로 표현된 것은 CPU임.
이 그림은 Fetch Stage와 Execute Stage를 세 명령에 대해서 그려놓은 것
0001은 메모리 특정 번지에 있는 데이터를 AC로 가져오라는 명령
0010은 AC에 있는 데이터를 메모리의 특정 번지에 저장하라는 명령
0101은 AC에 있는 내용과 메모리의 특정 번지에 있는 데이터를 서로 덧셈을 한 다음에 그 결과값을 AC에 저장하라는 명령
즉, 여기 보이는 세 개의 명령은 940번지에 있는 데이터를 AC로 가져왔다가 거기에 941번지에 있는 데이터를 더하고 더한 결과 값을 941번지에 저장하라는 명령 (a=a+b)
Memory 안
맨 앞에 명령들 써 있음. (1, 5, 2)
300번지는 940 주소의 데이터를 가져오고 301 번지의 명령은 941 번지의 데이터와 덧셈을 하고 302 번지에 있는 명령은 941번지에 저장하라는 세 명령을 표현한 것임.
Fetch Stage
fetch stage를 시작하기 전
PC : 300
IR : 이전 실행 명령
이 상태에서 fetch stage가 시작되는 것임
(1) MAR ← PC, PC++
(2) memory read, MBR ← (MAR에 저장된 번지의 명령)
(3) IR ← MBRfetch stage가 시작이 되면 300번지에 있는 명령을 가져올 것인데, PC의 값을 MAR로 옮김.
그리고 옮겨 놓는 순간 PC의 값은 하나 더해지게 됨.
(별일이 없으면 코드는 한 줄 한 줄 실행되는 것이기 때문에 fetch를 하면 다음 명령은 301번지라고 생각함)
memory read 신호가 주어지게 되면 MAR에 저장된 현재의 명령이 MBR로 이동하게 됨 (MBR에 있는 명령을 분석할 수 없음)
명령 분석을 하기 위해 300번지 명령(MBR에 있는 명령)을 IR로 옮김 → fetch stage가 끝남
fetch stage가 끝난 시점에서 PC는 1 증가되어 있음
Execute Stage
Execute Stage #1
(1) 명령 분석
(2) MAR ← IR의 주소 부분
(3) memory read, MBR ← (MAR에 저장된 번지의 데이터)
(4) AC ← MBR명령을 분석할 때에는 IR의 operation code 확인
Execute Stage #2
(1) 명령 분석
(2) MAR ← IR의 주소 부분
(3) memory read, MBR ← (MAR에 저장된 번지의 데이터)
(4) AC ← AC + MBR
Execute Stage #3
(1) 명령 분석
(2) MAR ← IR의 주소 부분, MBR ← AC
(3) memory write, (MAR에 저장된 번지의 memory 공간) ← MBR
데이터를 쓸 때에는, 어디에 쓸지, 무엇을 쓸지 알려줘야 함.
IR의 주소 부분은 MAR에 저장, MBR에는 무엇을 쓸지 저장
MBR에 있는 데이터가 MAR이 가리키는 공간으로 저장됨.
Interrupts
명령을 실행하다가 실행 중이던 프로그램을 중단 시키는 상황이 발생함. 이것이 interrupt
정상적인 프로그램의 실행을 중단해야 하는 이벤트.
Classes of Interrupts (인터럽트가 걸리는 이유)
- Program
- ✨ 하드웨어 interrupt임!! ✨
- instruction을 실행하다가 프로그램을 중단시킴
- 계산했는데 오버플로우가 발생할 때 (결과가 잘못된 결과)
- 나누기 0 (프로그램을 실행할 수 없기 때문에 프로그램이 중단됨)
- illegal한 machine instruction을 실행하려고 할 때 (잘못된 기계 명령)
- 프로그램 자체를 잘못 작성함
- 프로그램은 잘 작성했는데 중간에 오류가 발생함 (하드디스크에서 메모리로 올라오는 과정, 메모리에서 CPU로 오는 과정)
- 다른 사람이 나의 메모리 영역을 access해서 instruction을 고침
- 데이터 영역에 instruction을 저장
- 메모리 영역에서 다른 사람의 공간을 침범할 때
- 소프트웨어 interrupt가 아님. 프로그램이 발생시키는 interrupt도 아님
- 프로그램을 실행하는 과정에서 실행하던 instruction과 관련된 하드웨어가 interrupt를 발생시킨 것임
- 프로그램이 interrupt가 발생하면 OS가 프로그램을 중단시킴. 그리고 화면에 오류 메시지를 띄움.
- Timer
- ✨ 하드웨어 interrupt임!! ✨
- timer가 interrupt를 걺
- 일단 중단했다가 다른 프로그램을 실행하고 나중에 자기 차례가 되면 다시 실행을 할 수 있음
- I/O
- ✨ 하드웨어 interrupt임!! ✨
- I/O Controller가 I/O Device에 인터럽트를 걺
- I/O 작업을 하려고 할때 인터럽트가 걸린다고 착각함 ❌ → I/O 작업이 시작할 때는 인터럽트가 안 걸림. I/O 작업이 끝났을 때 인터럽트가 걸림
- I/O 디바이스가 I/O에 완료 또는 오류사항을 통보하기 위해서 인터럽트를 걺.
- 프로그램을 계속 실행할 수 있고, 프로그램을 바꿀 수도 있음 (I/O가 끝날 때 인터럽트 걸리므로)
- Hardware failure
- ✨ 하드웨어 interrupt임!! ✨
- power나 memory 관련. 하드웨어에 문제가 생겨서 발생하는 인터럽트.
- 일시적인 오류이면 계속 실행할 수도 있고, 문제가 있으면 시스템을 중단해야 하는 상황일 수도 있음.
인터럽트가 발생을 하게 되면 이 인터럽트를 처리하는 것은 OS임.
인터럽트 상황들을 전부 확인하고 거기에 따라서 적절하게 프로그램을 계속 실행할지 아니면 중단을 시킬지 아니면 일시 중단을 하고 다른 프로그램으로 바꿀지 하는 것들을 결정을 하게 됨.
대부분의 I/O Devices은 프로세서(CPU)보다 속도가 느림.
Program Flow of Control With of Without Interrupts & Timing Diagram
I/O interrupt를 사용하는 이유
I/O interrupt 없이 시스템을 만들면 굉장히 비효율적이고 느린 시스템이 만들어짐 (I/O Device가 CPU보다 느리기 때문)
(a) No interrupts
① → ④ → I/O Command → ⑤ → WRITE → ④ → I/O Command → ⑤ → ② ...
interrupt를 사용하지 않는 시스템.
입출력은 OS가 함 (프로그램이 하지 못함. ex : scanf나 printf 안에는 read나 write가 있고 이것들은 OS에게 입출력을 해달라고 요청하는 문장임. 실제 입출력을 하는 코드는 OS가 가지고 있음
- 왼쪽 그림의 오른쪽에 있는 I/O Program이 실제 입출력을 하는 OS 코드.
- I/O Command : I/O Device에게 입력/출력을 하라고 명령하는 문장. 시간이 굉장히 많이 걸림.
- 명령을 하기 전 ④번 코드가 있고, 입출력을 하면 ⑤번 코드가 실행이 됨.
- ④번 코드 : 입출력을 하기 위해 필요한 여러 가지 작업들. 어떠한 데이터를 출력할 것인지, 어떤 데이터를 어디로 입력을 받을 건지 등을 지정하는 작업들을 포함해서 입출력을 위한 preprocessing을 하는 부분.
- ⑤번 코드 : I/O가 정상적으로 잘 끝났는지, I/O를 진행하는 도중에 오류가 발생했는지에 대해 알려줘야 함. 정상적으로 잘 끝났다면 데이터가 입출력됨. 그러나 오류가 발생했으면 프로그램은 중단되거나 화면에 오류 메시지를 띄우게 됨. 이러한 작업을 하기 위한 코드
- 오른쪽 그림의 Timing Diagram : Short I/O wait
- 중간에 있는 까만 부분은 I/O Device가 작업을 끝날 때까지 CPU가 놀고 있는 구간
- 까만 부분이 길기 때문에 만약 Interrupt가 없다면 CPU는 항상 놀고 있게 될 것임.


(b) Interrupts; short I/O wait
- ① 을 실행하고 write를 해야되면 ④ 를 실행함. I/O Device가 작업을 시작하면 CPU는 기다리지 않고 바로 User Program으로 돌아와서 ② 의 실행을 시작함. (CPU : ② , I/O Device : 출력 / 동시에 작업을 하고 있는 것임)
- I/O 작업이 끝나면 ⑤를 실행해야 함. CPU에게 ⑤의 시작을 알려주기 위해 INTERRUPT 사용
- interrupt가 발생하면 누가, 왜 인터럽트를 발생시켰는지부터 확인함 (interrupt 종류에 따라서 실행해야 하는 코드가 다르기 때문)
- 따라서 ⑤ 작업은 Interrupt Handler가 작업을 함 (I/O 프로그램이 작업하는 것이 아님)
- 오른쪽 그림 Timing Diagram : Short I/O wait
- 까만 부분을 메꾸게 되면서 CPU가 계속 쉬지 않고 돌아갈 수 있음 → 실행시간이 훨씬 짧아짐. 훨씬 더 효율적인 시스템이 됨


(c) Interrupts; long I/O wait
interrupt를 사용하지만 I/O 작업이 길어질 때의 그림
두 번째 WRITE에서 interrupt가 올 때까지 기다림. interrupt가 발생하면 5번 처리함.
어떤 종류의 인터럽트가 걸렸는지에 따라 프로그램이 완전히 중단되기도 하고, 다른 프로그램으로 바뀌기도 하고, 잠깐 인터럽트 처리를 하고 다시 실행을 하기도 함. 이것을 결정하는 것이 바로 OS의 Interrupt Handler가 하는 일임.
Interrupt Handler

왼편에 있는 1번부터 M까지 번호가 붙어있는 파란색 부분 : 프로그램 (User Program)
오른편에 있는 번호가 없는 부분 : Interrupt Handler
User Program의 i번째 instruction까지 실행을 함. → interrupt 걸림 → interrupt handler 프로그램을 실행을 함. → 실행 완료 후 다시 돌아가서 i+1번째 instruction부터 실행을 함
Interrupt handler는 인터럽트 종류에 따라서 오른쪽에 있는 파란색 부분의 코드가 달라짐. 당연히 인터럽트 작업은 OS에 있어서 가장 중요한 부분이기 때문에 OS의 일부임.
Instruction Cycle with Interrupts
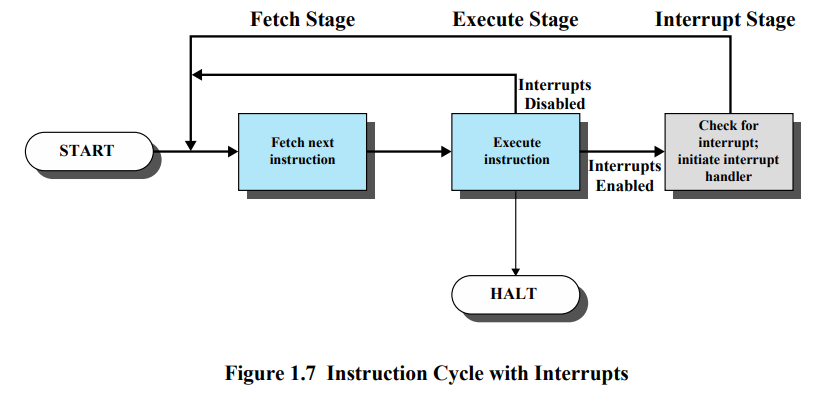
Fetch Stage → Execute Stage → Interrupt Stage
Execute Stage가 끝난 다음에 interrupt 처리를 함
만약 Interrupt가 발생하지 않는다면 Fetch와 Execute만 번갈아가며 실행할 것임.
항상 Execute Stage가 끝나면 PSW의 Interrupt stage를 확인함. 만약 Interrupt가 발생되면 Interrupt stage를 실행함.
Fetch Stage나 Execute Stage를 지나가고 있는 중에 Interrupt가 발생을 했다고 했을 때, 중간에 중단을 하지 않음. 무조건 Execute Stage가 다 끝난 다음에 Interrupt 처리를 함. → 하드웨어가 한 세트로 처리를 하기 때문에 중간에 멈추게 하지 못 함.
Interrupt Stage에서 하는 일
- 왜 Interrupt가 발생했는지 확인함. (어떠한 장치가 인터럽트를 발생시켰는지 하드웨어적으로 판단함)
- OS를 실행시킨 후, OS가 해당하는 인터럽트를 처리할 interrupt handler를 시작시킴 (인터럽트가 발생된 이유에 따라 interrupt handler가 달라짐)
- interrupt hanlder (프로그램)를 한 줄 한 줄 (fetch-execute) 실행함
Simple Interrupt Processing

CPU 안에 있는 Register인 PC, General Register에 있는 모든 값 등등
전부 다 안전한 저장 장소에 저장을 해야 나중에 이 프로그램을 다시 시작할 수 있음
안전한 저장 장소 = 메모리
CPU 안의 레지스터 값들을 안전한 곳에 저장하면서 프로그램은 언제든지 멈췄다가 다시 시작할 수 있게 됨.
CPU 안에 있는 모든 레지스터 값들을 메모리 안에 있는 Control Stack이라는 안전한 곳에 저장해 놓음. (작업이 끝나면 CPU 안에 있는 레지스터에 다시 집어넣음)
iterrupt 처리는 interrupt handler가 할 것이고, interrupt handler는 각각의 프로그램임.
Hardware
1. Device Controller나 다른 시스템 하드웨어가 인터럽트를 발생시킴. (즉, interrupt가 하드웨어적으로 발생함)
2. CPU는 interrupt가 발생했을 때, 지금 실행하고 있는 instruction을 끝까지 실행함.
3. interrupt 받았다고 acknowledge 보냄
4. CPU 안에 있는 여러 register 중, PC와 PSW의 값을 메인 메모리에 있는 Control Stack에 먼저 저장함
: 하드웨어적으로 처리하지 않으면 안 됨. 나머지 register들은 소프트웨어적으로 처리하는 것이 더 싸고 효율적임
5. interrupt 처리를 해야하는 interrupt handler(OS)의 시작 주소를 PC에 저장함. (하드웨어적으로)
6. Software 처리 시작
Software
: interrupt handler 프로그램이 실행을 하는 부분
: Hardware와 Software가 만나는 부분이 굉장히 많은데 그것을 OS가 처리함
: OS 또는 Interrupt Handler가 처리
1. 나머지 중요한 CPU 정보들, process state를 저장함.
2. interrupt의 발생 이유 확인 후, 적절한 처리
3. process state를 CPU에 복구함
4. PC, PSW를 복구함.
만약 PC 값을 먼저 저장하는 경우 인터럽트 핸들러의 작업이 끝나버리고 새로운 프로그램이 바로 시작되어 버린다.
따라서 다른 중요한 정보들을 모두 저장한 후 새로운 프로그램이 시작되게 하기 위하여 .... PC, PSW를 따로 저장함!!
'전공 > OS' 카테고리의 다른 글
| CH03. Process Description and Control (1) (0) | 2024.04.23 |
|---|---|
| CH02. Operating System Overview (2) (0) | 2024.04.23 |
| CH02. Operating System Overview (1) (1) | 2024.04.23 |
| CH01. Computer System Overview (3) (0) | 2024.04.23 |
| CH01. Computer System Overview (1) (0) | 2024.04.22 |




댓글